
In this guide, I’ll show you how to use Screaming Frog’s Custom Extraction feature to scrape schema markup, HTML, inline JavaScript and more using XPath and regex. I’ve included plenty of Custom Extraction examples that you can copy or modify for your own Screaming Frog crawls.
Why Use the Custom Extraction Feature?
Screaming Frog scrapes a lot of critical information by default; page titles, H1 elements, canonical tags, etc. But what if you want to pull other data points into your site crawls?
With Custom Extraction, you can program Screaming Frog to scrape just about any information you want. Once you get a handle on how to use it, you can conduct more advanced site crawls and analysis.
For example, here are a few ways that I’ve used Custom Extraction to develop insights and recommendations for my clients’ SEO strategies:
- Extract publish date to analyze the SEO performance of content by age
- Extract the comment count of blog articles to show the client which topics drive the most engagement
- Extract the product availability property from an ecommerce site’s schema markup to help understand how Google was indexing out of stock products
How to Use Screaming Frog Custom Extraction
You can access the Custom Extraction feature in the Configuration dropdown under Custom > Extraction.
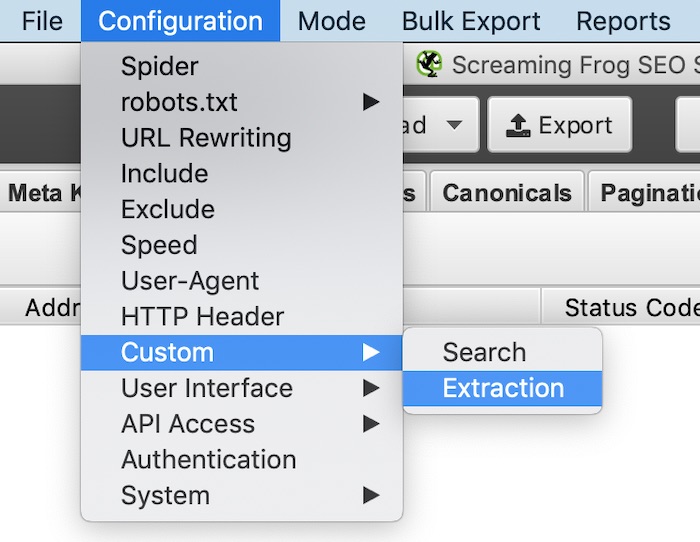
Next, you set up your extraction rules. This guide will give you all the instruction you’ll need to create your own.

- Extractor Name: The name will appear as the column header for your custom extractions
- Extraction Method: Choose XPath, Regex or CSSPath
- Rule: This is where you’ll enter the XPath or regex syntax that we cover in this guide
- Extraction Filter: Choose Extract Inner HTML, Extract HTML Element, Extract Text, or Extract Function Value (note that these options are not available with regex)
As you run crawls using Custom Extraction, you may find yourself toggling between the Extraction Filter options in order to arrive at the format you want for your data. Several of the examples covered in this guide require a particular Extraction Filter to be selected.
The data you extract is available in the Custom tab. Set the Filter dropdown to Extraction.
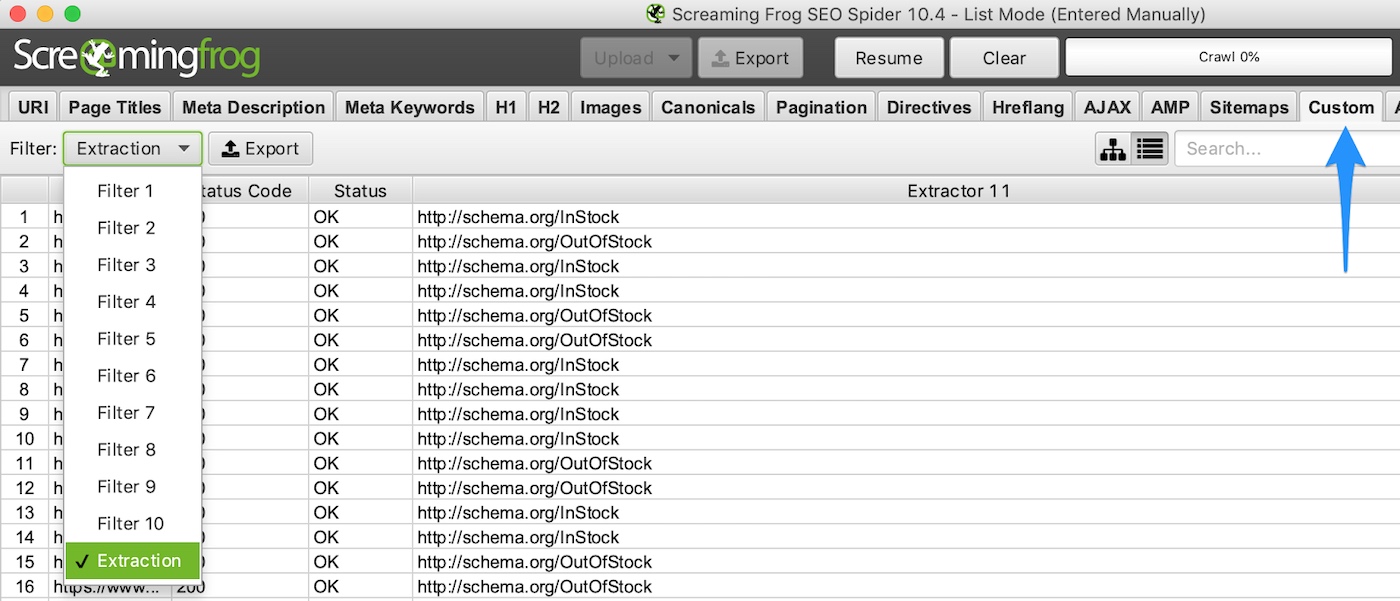
It’s also available as a column in the Internal tab alongside all of the default fields that Screaming Frog populates.
Custom Extraction with XPath
What is XPath?
XPath stands for XML Path Language. XPath can be used to navigate through elements and attributes in an XML document.
When to Use XPath
Use XPath to extract any HTML element of a webpage. If you want to scrape information contained in a div, span, p, heading tag or really any other HTML element, then go with XPath.
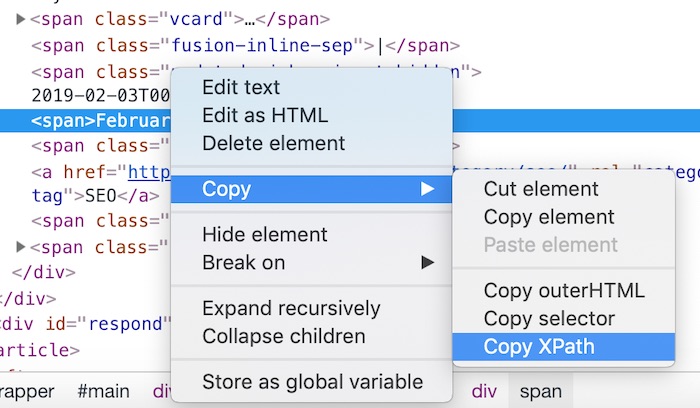
Google Chrome has a feature that makes writing XPath easier. Using the Inspect tool, you can right-click on any element and copy the XPath syntax. It’ll often be the case that you’ll need to modify what Chrome gives you before pasting the XPath into Screaming Frog, but it at least gets you started.
Basic Syntax for XPath Web Scraping
Here is the basic syntax for XPath web scraping:
| Syntax | Function |
|---|---|
| // | Search anywhere in the document |
| / | Search within the root |
| @ | Select a specific attribute of an element |
| * | Wildcard, used to select any element |
| [ ] | Find a specific element |
| . | Specifies the current element |
| .. | Specifies the parent element |
Here are common XPath functions:
| Operator | Function |
|---|---|
| starts-with(x,y) | Checks if x starts with y |
| contains(x,y) | Checks if x contains y |
| last() | Finds the last item in a set |
| count(XPath) | Counts occurrences of the XPath extraction |
XPath Custom Extraction Examples
In the tables below, you can copy the syntax in the XPath column and paste it into Screaming Frog to perform the extraction described in the Output column. Tweak the syntax as you'd like in order to customize the extraction to your needs.
How to Extract Common HTML Elements
| XPath | Output |
|---|---|
| //h1 | Extract all H1 tags |
| //h3[1] | Extract the first H3 tag |
| //h3[2] | Extract the second H3 tag |
| //div/p | Extract any <p> contained within a <div> |
| //div[@class='author'] | Extract any <div> with class "author" |
| //p[@class='bio'] | Extract any <p> with class "bio" |
| //*[@class='bio'] | Extract any element with class "bio" |
| //ul/li[last()] | Extract the last <li> in a <ul> |
| //ol[@class='cat']/li[1] | Extract the first <li> in a <ol> with class "cat" |
| count(//h2) | Count the number of H2's (set extraction filter to "Function Value") |
| //a[contains(.,'click here')] | Extract any link with anchor text containing "click here" |
| //a[starts-with(@title,'Written by')] | Extract any link with a title starting with "Written by" |
How to Extract Common HTML Attributes
| XPath | Output |
|---|---|
| //@href | Extract all links |
| //a[starts-with(@href,'mailto')]/@href | Extract link that starts with “mailto” (email address) |
| //img/@src | Extract all image source URLs |
| //img[contains(@class,'aligncenter')]/@src | Extract all image source URLs for images with the class name containing “aligncenter” |
| //link[@rel='alternate'] | Extract elements with the rel attribute set to “alternate” |
| //@hreflang | Extract all hreflang values |
How to Extract Meta Tags (including Open Graph and Twitter Cards)
I recommend setting the extraction filter to “Extract Inner HTML” for these ones.
Extract Meta Tags:
| XPath | Output |
|---|---|
| //meta[@property='article:published_time']/@content | Extract the article publish date (commonly-found meta tag on WordPress websites) |
Extract Open Graph:
| XPath | Output |
|---|---|
| //meta[@property='og:type']/@content | Extract the Open Graph type object |
| //meta[@property='og:image']/@content | Extract the Open Graph featured image URL |
| //meta[@property='og:updated_time']/@content | Extract the Open Graph updated time |
Extract Twitter Cards:
| XPath | Output |
|---|---|
| //meta[@name='twitter:card']/@content | Extract the Twitter Card type |
| //meta[@name='twitter:title']/@content | Extract the Twitter Card title |
| //meta[@name='twitter:site']/@content | Extract the Twitter Card site object (Twitter handle) |
How to Extract Schema Markup in Microdata Format
These XPath rules can be used when a website’s schema markup is in microdata format, like this:

If it’s in JSON-LD format, then jump to the section on how to extract schema markup with regex.
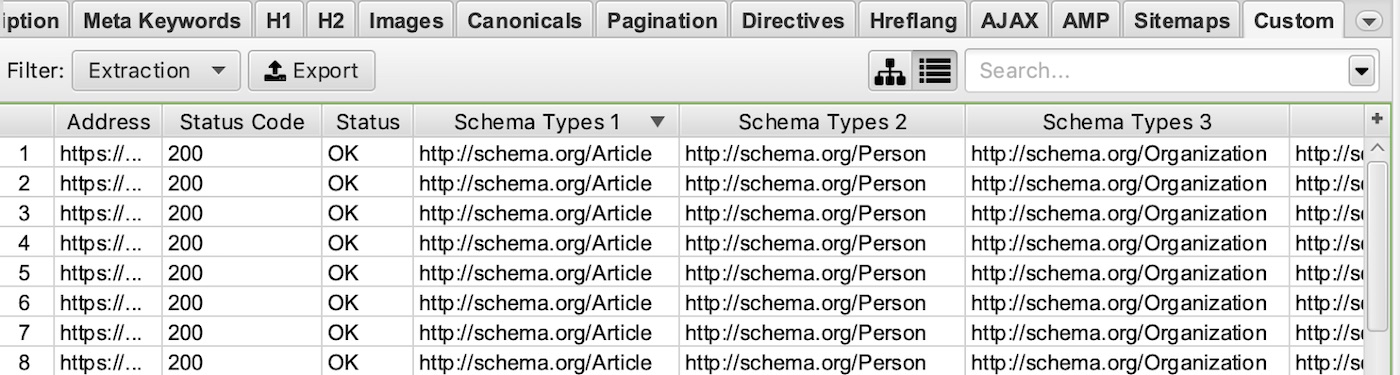
Extract Schema Types:
| XPath | Output |
|---|---|
| //*[@itemtype]/@itemtype | Extract all of the types of schema markup on a page |
Example Screaming Frog Custom Extraction:
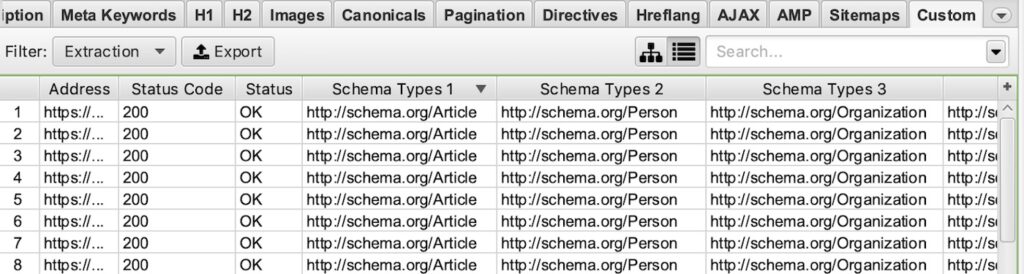
Extract Breadcrumb Schema:
| XPath | Output |
|---|---|
| //*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop]/a/@href | Extract all breadcrumb links |
| //*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop][1]/a/@href | Extract the first breadcrumb link |
| //*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop] | Extract breadcrumb names (set extraction filter to “Extract Text”) |
| count(//*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop]) | Count the number of breadcrumb list items (set extraction filter to “Function Value”) |
Example Screaming Frog Custom Extraction:
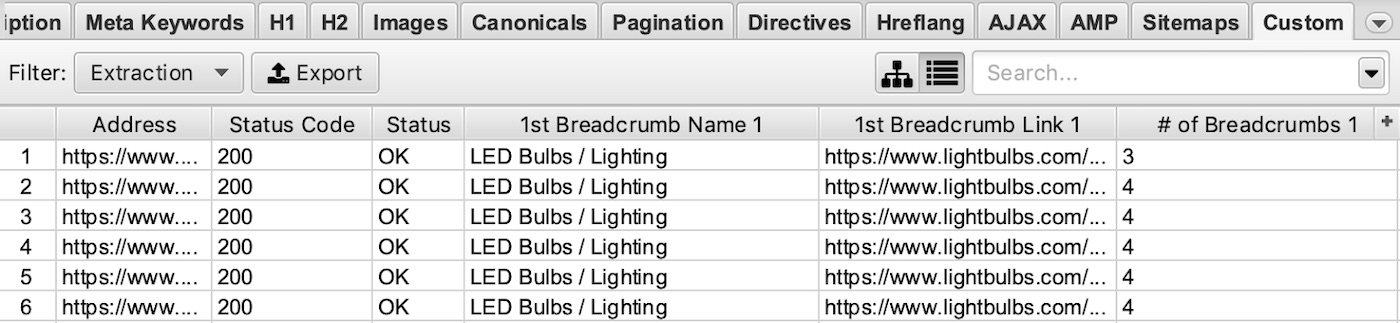
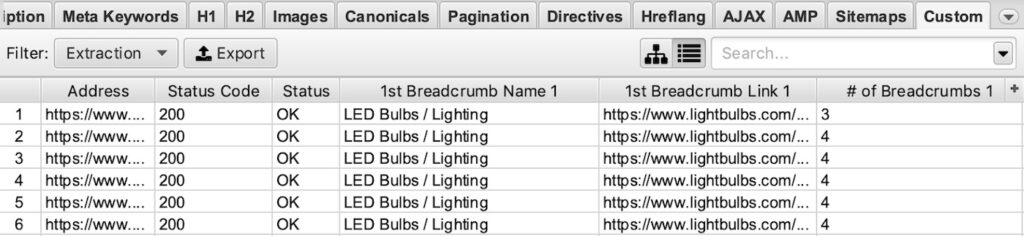
Extract Product Schema:
| XPath | Output |
|---|---|
| //*[@itemprop='name']/@content | Extract product name |
| //*[@itemprop='description']/@content | Extract product description |
| //*[@itemprop='price']/@content | Extract product price |
| //*[@itemprop='priceCurrency']/@content | Extract product currency |
| //*[@itemprop='availability']/@href | Extract product availability |
| //*[@itemprop='sku']/@content | Extract product SKU |
Example Screaming Frog Custom Extraction:
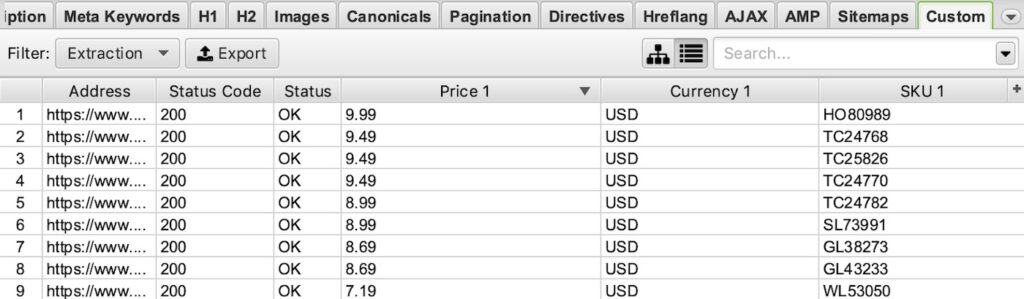
Extract Review Schema:
| XPath | Output |
|---|---|
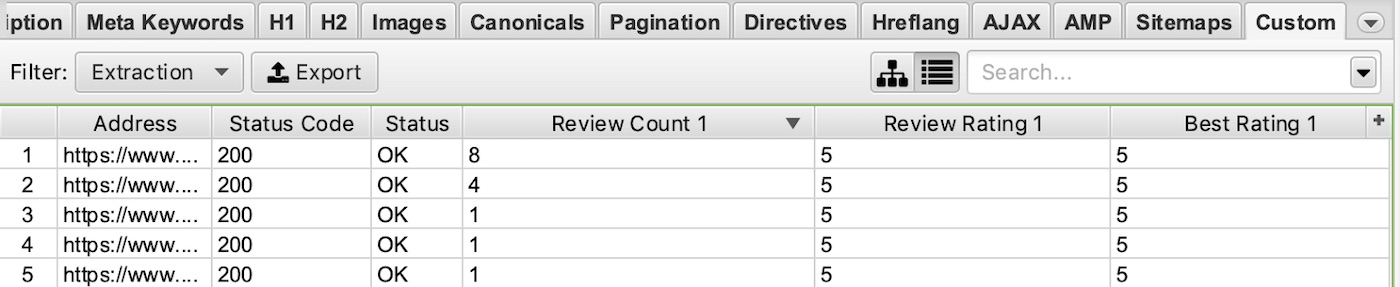
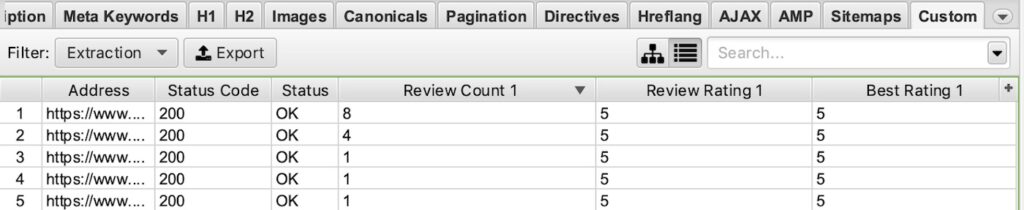
| //*[@itemprop='reviewCount'] | Extract review count |
| //*[@itemprop='ratingValue'] | Extract rating value |
| //*[@itemprop='bestRating'] | Extract best review rating |
| //*[@itemprop='review']/*[@itemprop='name'] | Extract review name |
| //*[@itemprop='review']/*[@itemprop='author'] | Extract review author |
| //*[@itemprop='review']/*[@itemprop='datePublished']/@content | Extract the publish date of reviews |
| //*[@itemprop='review']/*[@itemprop='reviewBody'] | Extract the body content of reviews |
Example Screaming Frog Custom Extraction:
Extract Local Business & Organization Schema:
| XPath | Output |
|---|---|
| //*[contains(@itemtype,'Organization')]/*[@itemprop='name'] | Extract the organization's name |
| //*[@itemprop='address']/*[@itemprop='streetAddress'] | Extract the street address |
| //*[@itemprop='address']/*[@itemprop='addressLocality'] | Extract the address locality |
| //*[@itemprop='address']/*[@itemprop='addressRegion'] | Extract the address region |
| //*[@itemprop='telephone'] | Extract the telephone number |
| //*[@itemprop='sameAs']/@href | Extract the "sameAs" links |
Example Screaming Frog Custom Extraction:


Extract Article Schema:
| XPath | Output |
|---|---|
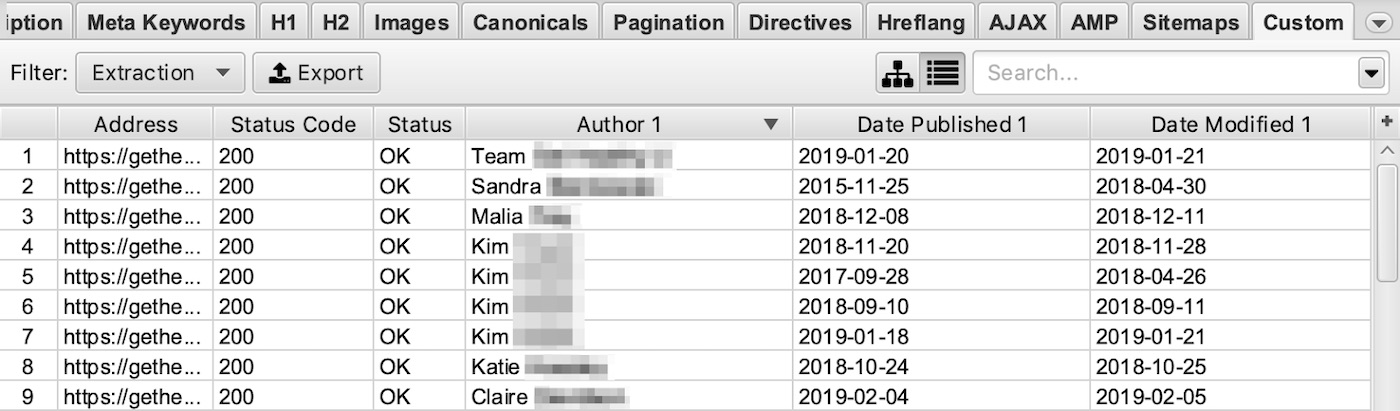
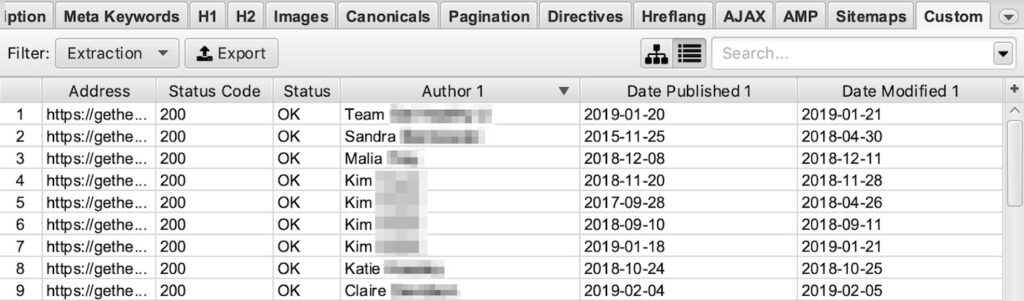
| //*[contains(@itemtype,'Article')]/*[@itemprop='headline'] | Extract the article headline |
| //*[@itemprop='author']/*[@itemprop='name']/@content | Extract author name |
| //*[@itemprop='publisher']/*[@itemprop='name']/@content | Extract publisher name |
| //*[@itemprop='datePublished']/@content | Extract publish date |
| //*[@itemprop='dateModified']/@content | Extract modified date |
Example Screaming Frog Custom Extraction:
Custom Extraction with Regex
What is regex?
A regular expression (regex) is a sequence of characters that define a search pattern. Usually this pattern is used by string searching algorithms for "find" or "find and replace" operations on strings...
When to Use Regex
Where XPath can extract HTML, it stops short of being able to extract inline JavaScript. This is where knowing regex comes in handy.
For example, with regex you can extract schema markup that’s in JSON-LD format. You can extract data out of tracking scripts, like scraping a web page’s Google Analytics tracking ID.
Basic Syntax for Regex
Regex can be complex and confusing, especially when you’re first learning it. This guide isn’t intended to teach you regex, so I recommend starting with this resource aimed at teaching marketers the basics of regex (their examples are specific to Google Analytics, which I think makes regex easier for marketers to grasp).
Next, I suggest reading through Google’s regex guide, which includes more helpful examples.
If you simply need a refresh, here’s a cheat sheet of the regex metacharacters:
Wildcards
| Syntax | Function |
|---|---|
| . | Match any 1 character |
| * | Match preceding character 0 or more times |
| ? | Match preceding character 0 or 1 time |
| + | Match preceding character 1 or more times |
| | | OR |
Anchors
| Syntax | Function |
|---|---|
| ^ | String begins with the succeeding character |
| $ | String ends with the preceding character |
Groups
| Syntax | Function |
|---|---|
| ( ) | Match enclosed characters in exact order |
| [ ] | Match enclosed characters in any order |
| - | Match any characters within the specified range |
Escape
| Syntax | Function |
|---|---|
| \ | Treat character literally, not as regex |
Regex Custom Extraction Examples
In the tables below, you can copy the syntax in the Regex column and paste it into Screaming Frog to perform the extraction described in the Output column. Tweak the syntax as you'd like in order to customize the extraction to your needs.
How to Extract Inline JavaScript
With regex, you can extract any code contained within <script> tags. For marketers, this means you can extract information like clients’ tracking ID’s used with their analytics or advertising platforms. Here are a few examples of that:
| Regex | Output |
|---|---|
| ["'](UA-.*?)["'] | Extract the Google Analytics tracking ID |
| ["'](AW-.*?)["'] | Extract the Google Ads conversion ID and/or remarketing tag |
| ["'](GTM-.*?)["'] | Extract the Google Tag Manager and/or Google Optimize ID |
| fbq\(["']init["'], ["'](.*?)["'] | Extract the Facebook Pixel ID |
| \{ti:["'](.*?)["']\} | Extract the Bing Ads UET tag |
| adroll_adv_id = ["'](.*?)["'] | Extract the AdRoll Advertiser ID |
| adroll_pix_id = ["'](.*?)["'] | Extract the AdRoll Pixel ID |
How to Extract Schema Markup in JSON-LD Format
These regex rules can be used when a website’s schema markup is in JSON-LD format, like this:

If it’s in microdata format, then jump to the section on how to extract schema markup with XPath.
Extract All Schema Markup and Schema Types:
| Regex | Output |
|---|---|
| ["']application/ld\+json["']>(.*?)</script> | Extract all of the JSON-LD schema markup |
| ["']@type["']: *["'](.*?)["'] | Extract all of the types of JSON-LD schema markup on a page |
Example Screaming Frog Custom Extraction:
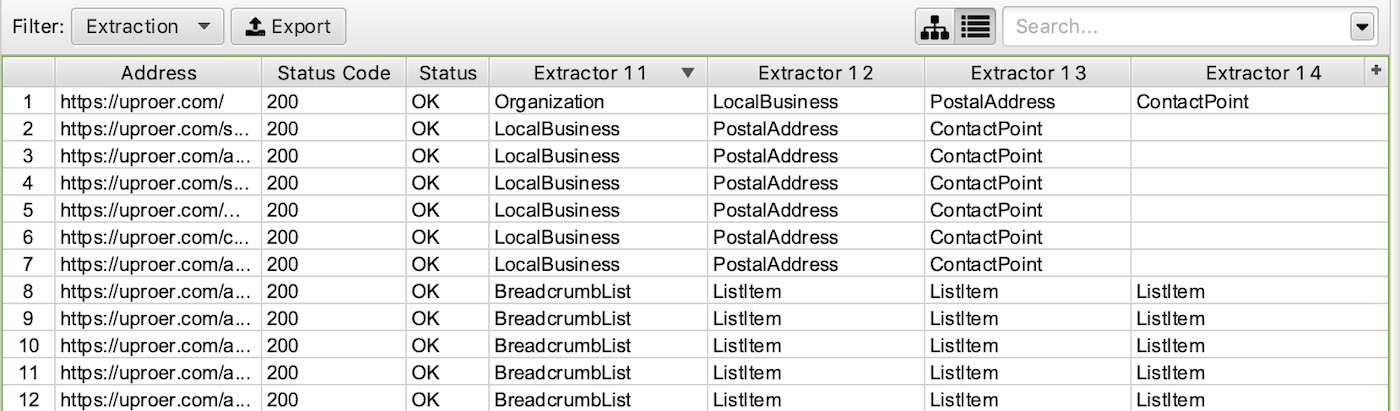
Extract Breadcrumb Schema:
| Regex | Output |
|---|---|
| ["']item["']: *\{["']@id["']: *["'](.*?)["'] | Extract breadcrumb links |
| ["']item["']: *\{["']@id["']: *["'].*?["'], *["']name["']: *["'](.*?)["'] | Extract breadcrumb names |
Extract Product Schema:
| Regex | Output |
|---|---|
| ["']@type["']: *["']Product["'].*?["']name["']: *["'](.*?)["'] | Extract product name |
| ["']@type["']: *["']Product["'].*?["']description["']: *["'](.*?)["'] | Extract product description |
| ["']@type["']: *["']Product["'].*?["']price["']: *["'](.*?)["'] | Extract product price |
| ["']@type["']: *["']Product["'].*?["']priceCurrency["']: *["'](.*?)["'] | Extract product currency |
| ["']@type["']: *["']Product["'].*?["']availability["']: *["'](.*?)["'] | Extract product availability |
| ["']@type["']: *["']Product["'].*?["']sku["']: *["'](.*?)["'] | Extract product SKU |
Extract Review Schema:
| Regex | Output |
|---|---|
| ["']reviewCount["']: *["'](.*?)["'] | Extract review count |
| ["']ratingValue["']: *["'](.*?)["'] | Extract rating value |
| ["']bestRating["']: *["'](.*?)["'] | Extract best rating |
Extract Local Business & Organization Schema:
| Regex | Output |
|---|---|
| ["']@type["']: *["']Organization["'].*?["']name["']: *["'](.*?)["'] | Extract organization name |
| ["']streetAddress["']: *["'](.*?)["'] | Extract the street address |
| ["']addressLocality["']: *["'](.*?)["'] | Extract the address locality |
| ["']addressRegion["']: *["'](.*?)["'] | Extract the address region |
| ["']telephone["']: *["'](.*?)["'] | Extract the telephone number |
| ["']sameAs["']: *\[(.*?)\] | Extract the "sameAs" links |
Extract Article or BlogPosting Schema:
| Regex | Output |
|---|---|
| ["']headline["']: *["'](.*?)["'] | Extract article headline |
| ["']author["'].*?["']name["']: *["'](.*?)["'] | Extract author name |
| ["']publisher["'].*?["']name["']: *["'](.*?)["'] | Extract publisher name |
| ["']datePublished["']: *["'](.*?)["'] | Extract publish date |
| ["']dateModified["']: *["'](.*?)["'] | Extract modified date |
Additional Resources
Here are several great articles that provide additional perspective and examples:
- Screaming Frog’s web scraping resource
- Custom Extraction in Screaming Frog: XPath and CSSPath by Brian Shumway
- How to Use Xpath for Custom Extraction in Screaming Frog by PMG
If you have any useful XPath or regex extraction rules you’ve used, please let me know in the comments and I’ll add them to the guide.



