
Content and on-page elements often get the bulk of an SEO strategy’s attention. After all, you can’t rank for keywords if you don’t have content. But, what if search engines have problems crawling your content?
If you have a website that’s plagued with crawl issues and inefficiencies, then your content may never perform to its SEO potential. AJ Kohn explains this well:
“What I’ve observed over the last few years is that pages that haven’t been crawled recently are given less authority in the index. To be more blunt, if a page hasn’t been crawled recently, it won’t rank well.”
This guide will help you analyze and identify opportunities to make your website more efficient for search engines to crawl. These improvements will help to ensure that you’re getting the most SEO value out of your content.
Why Does Crawl Efficiency Matter?
You want search engines to spend their limited time and resources crawling the important resources on your site - not URLs that have errors, are of little to no business value, or ones that shouldn’t even be indexed.
Hidden issues could be causing Google to waste its crawl budget on low-value URLs at the expense of your SEO performance. By making your site more efficient to crawl, you can:
- Speed up indexing
- Improve organic rankings
- Contribute to faster page speed
What is Crawl Budget?
Crawl budget is the maximum number of site resources that Google will crawl in a given timeframe. Your website’s crawl budget is determined by two factors:
- Crawl rate limit: The maximum rate at which Google can fetch resources from your website without diminishing the site experience for your users.
- Crawl demand: The popularity and staleness of your content factors into how Google calculates its demand for indexing.
Once your crawl budget is established, Google will crawl your website up to that limit. If Google exhausts your crawl budget before reaching important web pages, it’s understandable that your SEO performance would suffer.
Do I Need to Worry About Crawl Budget?
Large websites, yes. Small websites, no.
Google advises that “if a site has fewer than a few thousand URLs” then webmasters don’t need to be concerned about crawl budget. Larger websites, often ecommerce stores and publishers, are more susceptible to issues that exhaust their crawl budgets.
This isn’t to say that smaller websites can’t benefit from working on improving crawl efficiency. It can improve the rate of indexing, help direct ranking signals to the right pages and speed up performance. But, they likely don’t need to worry about Google hitting its maximum crawl threshold.
Crawl budget optimization must be a strategic SEO initiative for any enterprise ecommerce company.
What’s My Website’s Crawl Budget?
Google doesn’t provide this figure directly, but there are ways to infer what your crawl budget might be.
Many articles on this subject will point you to the Crawl Stats report in Google Search Console. While helpful, this only reports on web pages crawled and not all of the resources, both internal and external, required to load these pages.
To check the Crawl Stats report in GSC, navigate from the left sidebar under “Legacy Tools & Reports”.
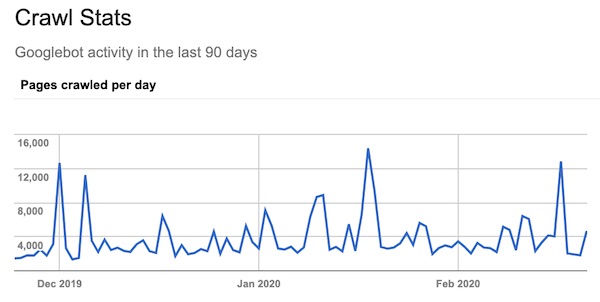
A better place to look is in your log files. Look at how many times Googlebot has requested assets from your web server over an extended time period and calculate a daily average.
What Counts Against My Crawl Budget?
Google states that “any URL that Googlebot crawls will count towards a site's crawl budget.” This means that HTML, CSS, JS and image files are all included. So too are alternate URLs, like hreflang and AMP.
Using Chrome’s DevTools, you can see how many resources are required to load a page under the Network tab:
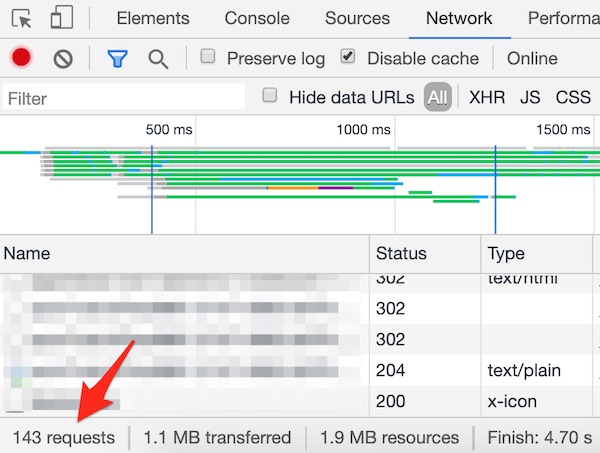
Disallowed URLs in your robots.txt file do not count against your crawl budget.
What Issues Commonly Impact Crawl Budget?
A variety of issues can impact crawl budget, but here’s a list of several of the most common:
- Poor server response
- Slow response time
- Numerous errors and/or redirect chains
- Long download times
- Low-value URLs
- URL parameters resulting from faceted navigation or user tracking (e.g., session identifiers)
- Soft errors, like the ones that can arise from having discontinued product pages
- Dynamically generated URLs, such as onsite search results
- “Infinite space” URLs, like when an ecommerce site has numerous filters (brand, color, size, etc.) that can be combined to create unique URLs in a nearly infinite amount of ways
- Duplicate content
- Duplicate URLs, like having mixed-case URLs or mixed-protocol URLs
- Trailing slash treatment (i.e., having both trailing slash and non-trailing slash version of URLs)
How to Improve Your Crawl Budget
Audit for Crawl Issues
The first step towards improving crawl efficiency is to identify the presence and severity of crawl issues on your website.
Before launching into a log file analysis, which we’ll cover in a moment, I recommend starting with higher-level analyses using Screaming Frog and Google Search Console. This will speed up your audit process and help you develop hypotheses that you can later explore in a log file analysis.
Screaming Frog
You can use Screaming Frog to mimic, more or less, how Googlebot crawls your website. Follow along with these configurations and analyze the results to identify crawl issues.
How to configure your crawl:
- Set user agent to “Googlebot (Smartphone)” (Configuration > User Agent)
- Apply these settings to the Spider Configuration (Configuration > Spider)
- Check “Follow Internal ‘nofollow’”
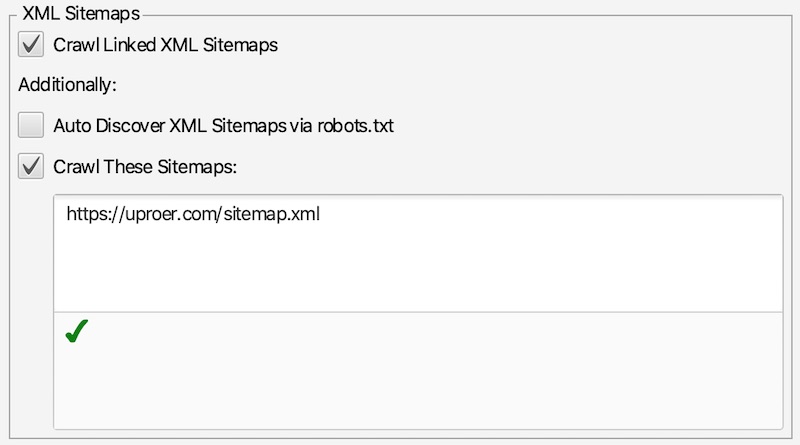
- Check “Crawl Linked XML Sitemaps” and provide your XML sitemap
- Connect Screaming Frog to Google Analytics & Google Search Console (Configuration > API Access)
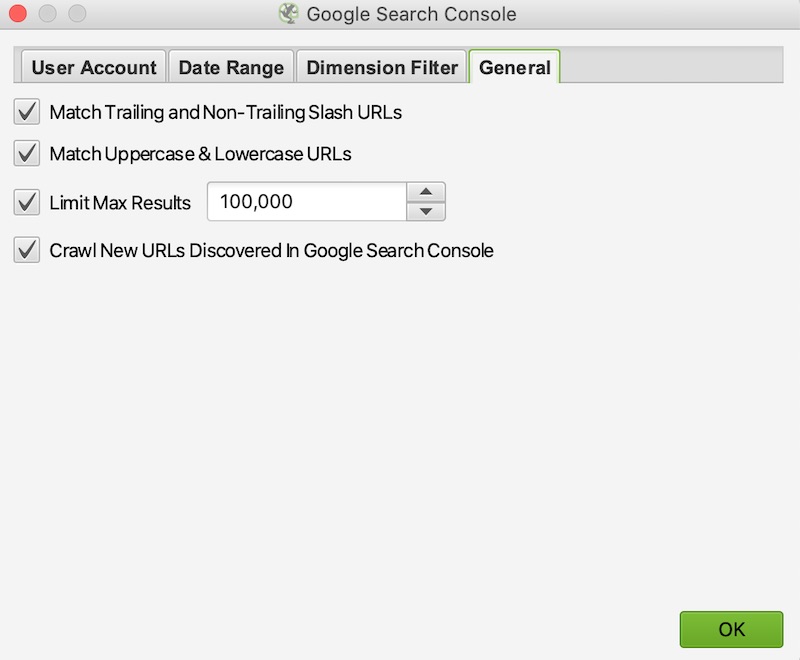
- Navigate to the “General” tab and check the option for “Crawl New URLs Discovered in Google Search Console”
- Run your crawl. Once completed, make sure to do a Crawl Analysis (Crawl Analysis > Start)
Key questions:
- How does the number of pages crawled compare to the actual size of your website?
- How many non-200 status code URLs were crawled?
- How many non-indexable HTML pages were crawled?
- Were any redirect chains identified?
- Is Googlebot crawling both HTTP and HTTPS URLs on your website?
- Were any URLs crawled that shouldn’t be?
- How many canonicalized or paginated URLs were crawled?
Use Screaming Frogs reports (under the Reports tab) to help you quickly answer these questions.
Google Search Console
Google Search Console’s Coverage reports are a great resource for identifying possible crawl issues. If you’re seeing too many “Valid” pages and/or a significant number of “Excluded” pages, then it’s worth digging a bit deeper.
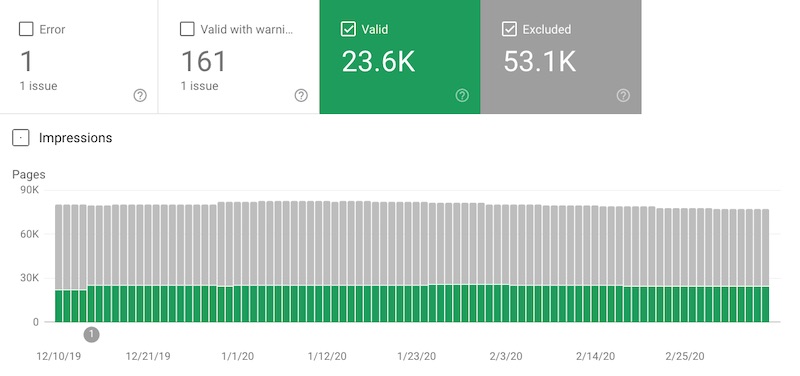
Here are a few Coverage reports to focus on. You can export up to 1,000 URLs from each report for further analysis.
Indexed, not submitted in sitemap
- Do you have a significant number of indexed pages that are not included in your XML sitemap? What are their URLs?
- Should these URLs be included in your XML sitemap? If not, should they even be crawled?

Discovered - currently not indexed
- This bucket of URLs are ones where, according to Google, “Google tried to crawl the URL but the site was overloaded.” If you have a lot of pages in this report, this could certainly indicate that you’re maxing out your crawl budget.
Soft 404
- These are URLs that have a “200” status code, but Google believes it might as well be an error page. For large ecommerce sites, you’ll often find URLs for out-of-stock products in this report.
Crawl anomaly
- These are URLs where Google encountered an error when crawling.
Excluded by ‘noindex’ tag
- If Google is excluding URLs that you don’t want to be indexed, then that’s a good thing. However, are you requiring Google to crawl tons of pages that you don’t want to appear in the index anyway?
Any report with the word “Duplicate” in its title
- These reports may indicate that Google spends a lot of energy crawling duplicate content, which could be stemming from poor canonicalization or excessive URL parameters.
There are many more reports worth analyzing, so don’t limit yourself to the ones featured above.
Analyze Your Log Files
If, after running a Screaming Frog crawl and reviewing your GSC Coverage reports, you’ve developed strong suspicions that you have crawl issues impacting SEO performance, then it’s time for a log file analysis.
Log files are your source of truth for how search engines are crawling your website. There is no better way to uncover and confirm crawl inefficiencies than conducting a log file analysis.
This isn’t a guide on log file analysis, so I’ll only be covering high-level information. But, I’ve linked to a few fantastic resources that can walk you through the process of analyzing log files.
What is a Log File?
Log files are text files stored on your server that record every request made by browsers, searchbots, and other user-agents. By filtering log files down to only include requests made by searchbots (e.g., Googlebot), you’re able to see which resources are being crawled and how often.
Log files contain a lot of information about each request. The most relevant data points for SEOs are:
- Timestamp
- Request URI
- HTTP status code
- User-agent
How to Analyze Log Files
Log files are generally huge files. Analyzing them with Excel can be problematic, so I recommend using Screaming Frog’s Log File Analyser or another log file analysis tool.
Here are some of my favorite resources for learning how to do a log file analysis:
- Log File Analysis for SEO by Portent
- 22 Ways To Analyse Logs Using The Log File Analyser by Screaming Frog
- The Ultimate Guide to Log File Analysis by Builtvisible
Fix Your Crawl Issues
Your analyses are complete and you’re now sitting with a laundry list of identified crawl issues: page errors, redirect chains, pesky parameters and other instances of wasted crawl budget.
You’re most likely going to need the help of a developer for the more technical items and perhaps a few team members to assist with the easy, yet tedious ones. Not to mention the buy-in from your client or upper management to allocate these resources to your project.
So, before you start firing off recommendations, consider this advice:
Prioritize the crawl issues you identified
Rank each issue by its expected level of effort and impact on performance. Then, start with ones that strike the best balance between feasibility and benefit. That way, you’ll fix important, low-hanging issues first, which will help prove out the value of this work.
Frame the issues in terms that non-SEOs can understand
If you’ll need buy-in from your client or upper management, then help them understand the business opportunity for addressing crawl budget improvements.
Instead of saying this:
A log file analysis revealed that Googlebot is wasting its crawl budget on canonicalized URL parameters.
Say this:
We discovered that Google is spending 80% of its time on pages that contribute just 2% to annual revenue.
Focus on fixing the root cause of the crawl issues
Don’t just put a band-aid on it. For example, let’s say you discovered that thousands of out-of-stock products are occupying Google’s crawl budget.
- Lazy fix: Implement 301 redirects
- Permanent fix: Educate the ecommerce team on how to manage OOS products in a way that’s more beneficial for SEO
- In this case, your recommendation should take into consideration factors like (1) the life cycle of your client's products, (2) the speed with which they sell out, (3) the likelihood that OOS products will return to inventory and (4) the capabilities of your client's CMS. Here's a great example from Mark Williams-Cook at Candour:
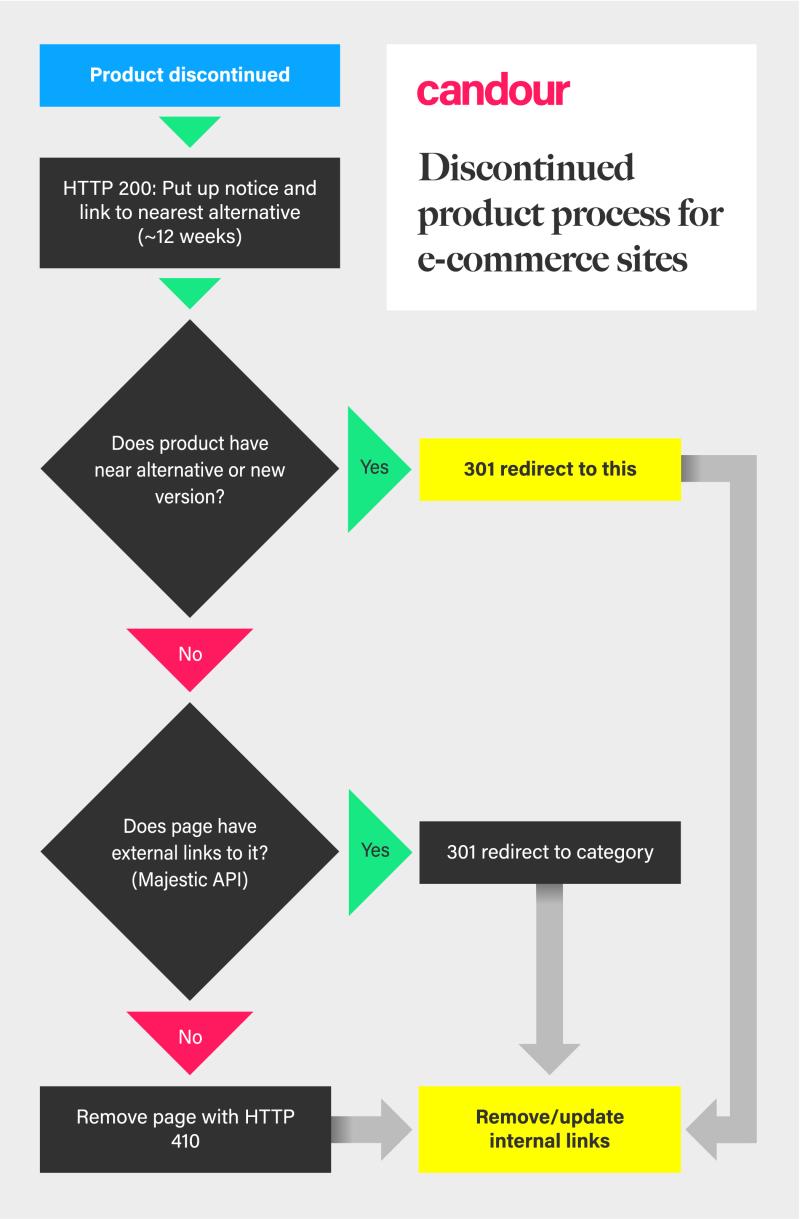
Make your recommendations specific
Don’t give your developer a vague recommendation and expect them to do the hard work of figuring out the correct solution. That’s a great way to have something done incorrectly (or not at all). At least meet your developer halfway by researching possible solutions that are specific to your site’s technology (i.e., CMS, hosting provider, plugin, etc.).
Common Ways to Improve Crawl Efficiency
Most crawl issues you identify will require some level of investigation to find the best solution. Listed below are several of the more common options that SEOs consider when improving crawl efficiency.
Internal Linking Practices
Managing the quantity and quality of your internal links can go a long way in improving crawl efficiency. Oftentimes, removing redundant or unnecessary links stemming from menus or paginated series is the key to reducing wasted crawl budget.
Audit your internal links in these areas:
- Menus
- Header and footer menus
- Sidebar menus and faceted navigation
- Pagination
- Article feed or product category pagination
Additionally, updating internal links to avoid redirects and page errors improves crawl efficiency.
Manage URL Parameters
URL parameters can waste crawl budget on any website, but they’re especially problematic for ecommerce websites. All of those sorting and filtering options have the potential of creating limitless URL variations that search engines can crawl.
There are ways to mitigate the impact of URL parameters on your crawl budget, but the best solution is often technology- and resource-dependent. Jes Scholz has a great guide on managing URL parameters, which outlines the pros and cons of several common methods:
- Limit (or eliminate) the use of URL parameters
- Use static URLs, when possible, for indexable content
- Use the rel=“canonical” tag
- Use the meta robots noindex tag
- Add “disallow” rules to the robots.txt file
- Use the Parameter Tool in Google Search Console
Use Crawl Directives
If you’re unable to fix the root cause of a crawl issue, then you’ll likely need to rely on a crawl directive. It’s important to understand how these directives affect not only crawling but other aspects of SEO like indexing and link equity:

Summary
As SEO gets more and more competitive, having a website that can be crawled thoroughly and efficiently may be the edge you need to maximize SEO performance. Check out these related resources from the Uproer blog to continue building your SEO skillset:



