
Wouldn’t it be great to know exactly how Googlebot is crawling your website? Unless you have the keys to the kingdom, you won’t get perfect information. But, we can get close!
Screaming Frog has nearly limitless configurations for just about any SEO use case you can imagine. This article presents a method to help you understand how Googlebot interacts with your initial HTML.
I’ve found this crawl configuration to be incredibly useful for identifying crawl inefficiencies that might sneakily be holding back your SEO performance. Read on to set up this crawl for yourself.
Instructions
1. Configure the crawl settings
From the top menu, navigate to Configuration > Crawl Config > Spider > Crawl. Configure the crawl settings exactly as you see them in the screenshot below.
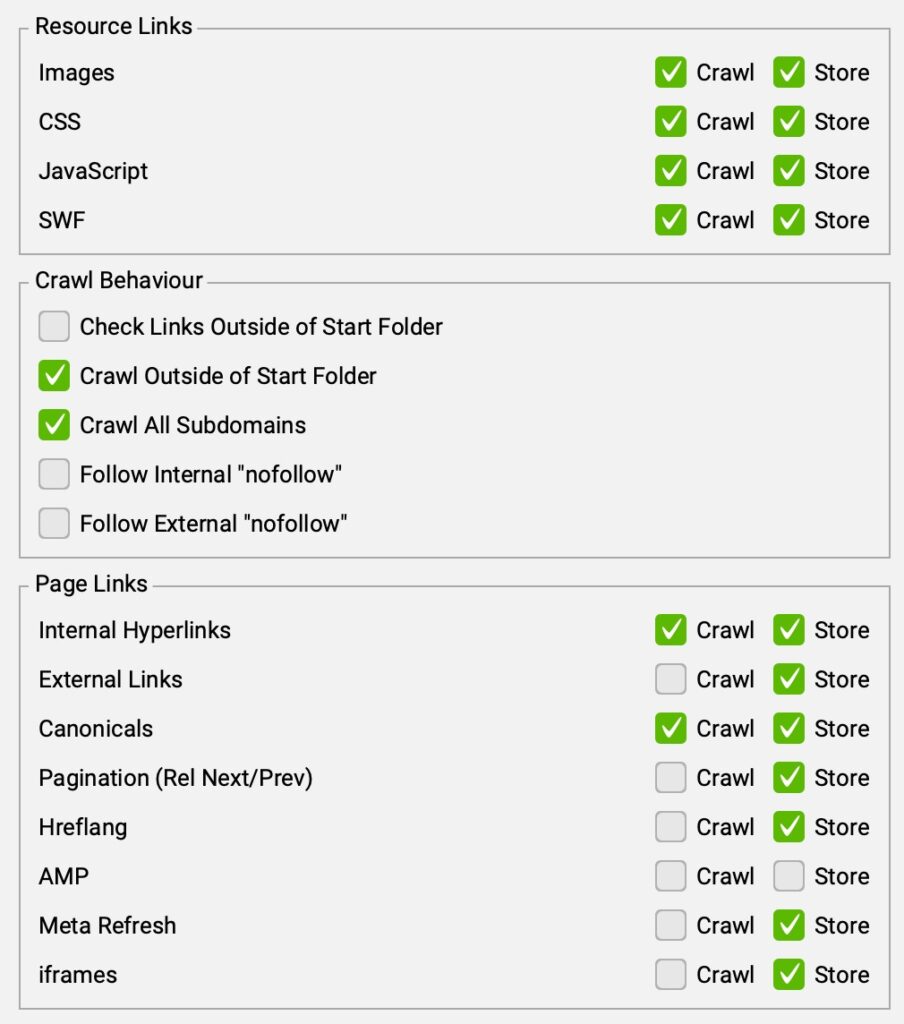
- Optionally, you can deselect “Images,” “CSS,” “JavaScrip,” and/or “SWF” to speed up your crawl.
2. Provide your XML sitemap(s)
While in the Crawl section, scroll down to “XML Sitemaps” and provide the XML sitemaps that represent the URLs you want Google to crawl and index.

- If you know your XML sitemaps are not set up properly or don’t contain all of the URLs you want crawled and indexed, I recommend addressing this issue first.
3. Follow redirect chains
Go to the Advanced settings (Configuration > Crawl Config > Spider > Advanced) and opt in to “Always Follow Redirects” (to identify redirect chains).

4. Opt in for structured data extraction
Go to the Extraction settings (Configuration > Crawl Config > Spider > Extraction) and opt in for structured data.

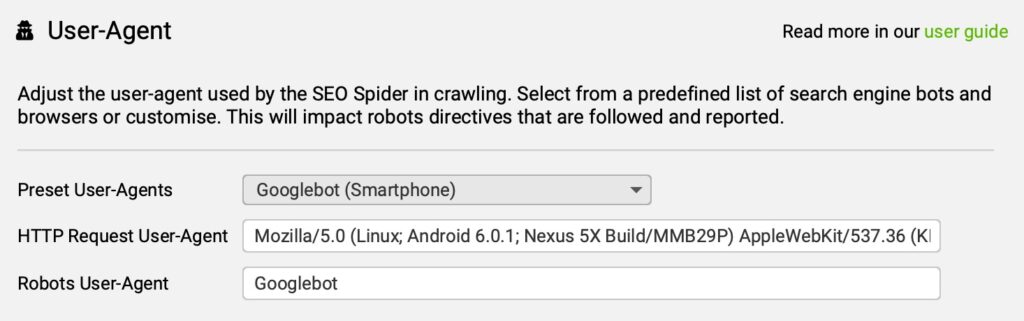
5. Set Googlebot as the user-agent
Navigate to Configuration > Crawl Config > User-agent and select "Googlebot (Smartphone)"
6. Start your crawl
From the top menu, select Mode > Spider. Enter the website's homepage and start the crawl.
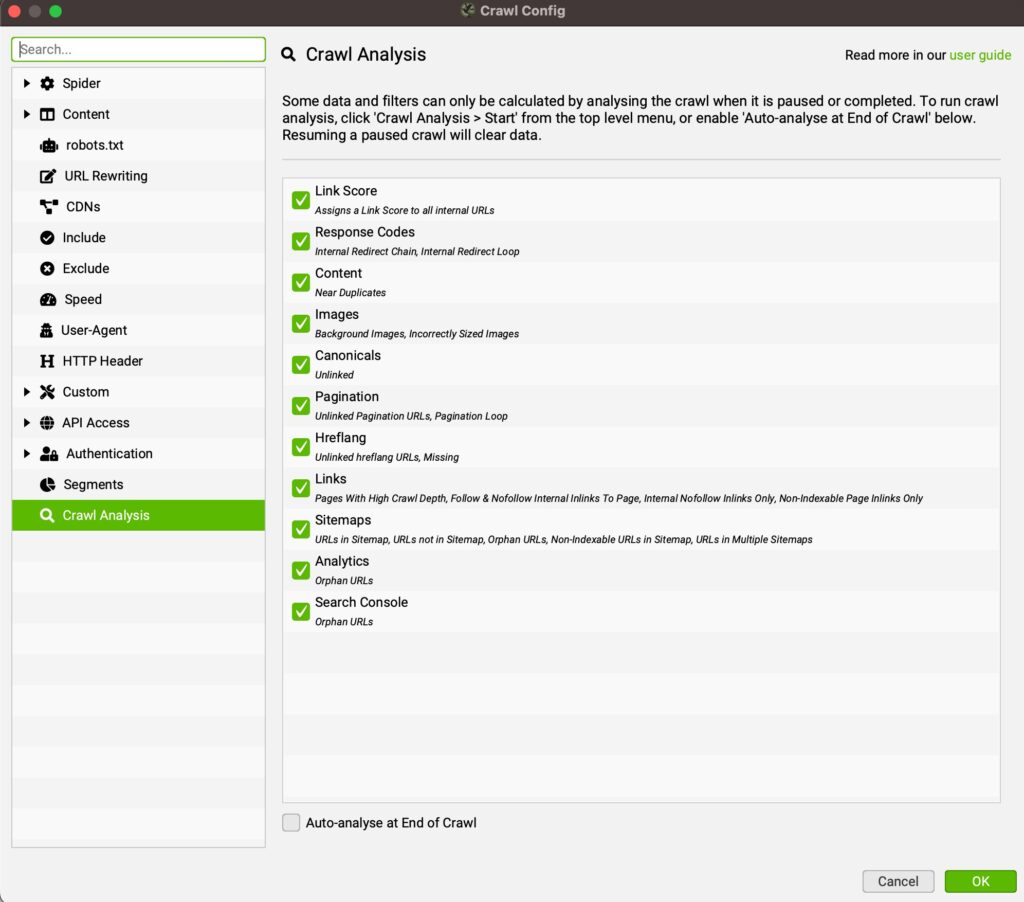
7. Run a “Crawl Analysis”
When the crawl is finished, navigate to Crawl Analysis > Start
What to Pay Attention to
Here’s a non-exhaustive list of potential issues to be on the lookout for:
Basic crawl inefficiencies
- Both HTTPS & HTTP URLs are being crawled
- Both ‘www’ and non-’www’ URLs are being crawled
- There are excessive internal redirects and page errors
Advanced crawl inefficiencies
- There are excessive non-indexable URLs with a 200 status code being crawled
- Noindexed URLs
- Canonicalized URLs
- There are seemingly limitless combinations of URL parameters being crawled
- Redirect chains are triggering excessive crawling or even time-outs
- Internal links are not present in the raw HTML
- Paginated links are not crawlable
Poor XML sitemap coverage
- The total of indexable URLs crawled far exceeds the size of the XML sitemap
- There are URLs not included in the XML sitemap that should be
- There are non-indexable URLs in the XML sitemap
- There are orphan URLs
Structured data issues
- Missing structured data
- Parse errors
- Validation errors
Speed Up Your Analysis with this Google Sheets Dashboard
It's not necessarily easy to spot potential issues in Screaming Frog's interface. That's why I created this dashboard in Google Sheets. Import your crawl data and the pre-built tables and charts will expedite your analysis.
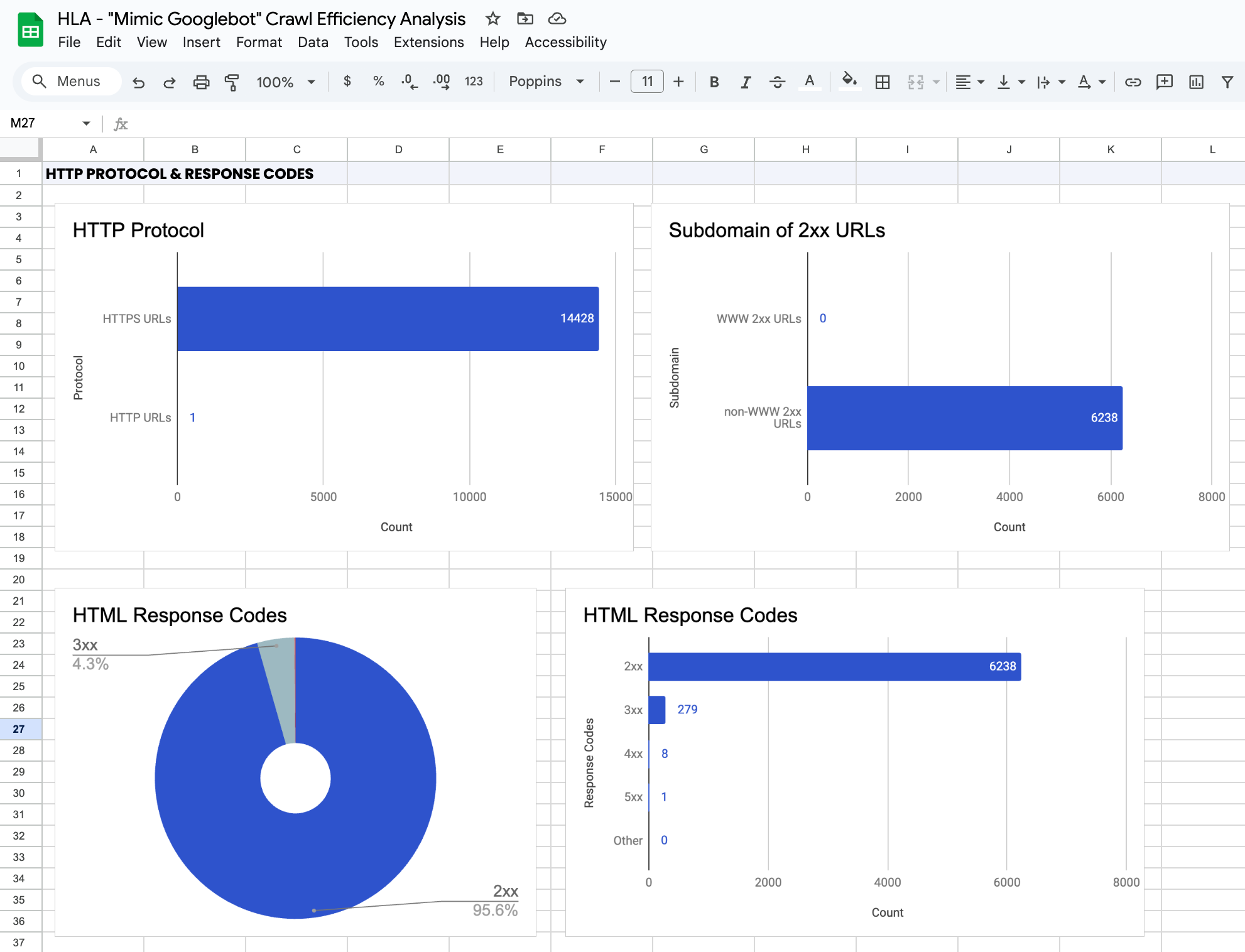
First, make a copy of the spreadsheet. Then, read the "Instructions" tab to import your data correctly.
Get Your Crawl On
Replicating Googlebot’s crawling habits with Screaming Frog can reveal hidden SEO inefficiencies that are holding back your performance. If you need help transforming the issues you identified into actionable recommendations, reach out to the Uproer team at [email protected]!
By the way, if you found this Screaming Frog article helpful, check out our popular guide on custom extraction.



